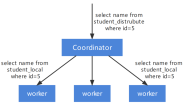
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
final StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("zookeeper.connect", "localhost:2181");
props.put("group.id", "metric-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "latest");
tableEnv.connect(new Kafka().version("0.10")
.topic("student").properties(props).startFromLatest())
.withFormat(new Json().deriveSchema())
.withSchema(new Schema().field("id", Types.INT())
.field("name", Types.STRING())
.field("password", Types.STRING())
.field("age", Types.INT())
.field("date", Types.STRING()))
.inAppendMode()
.registerTableSource("kafkaTable");
Table result = tableEnv.sqlQuery("SELECT * FROM " + "kafkaTable");
String targetTable = "clickhouse";
TypeInformation[] fieldTypes = {BasicTypeInfo.INT_TYPE_INFO
,BasicTypeInfo.STRING_TYPE_INFO
,BasicTypeInfo.STRING_TYPE_INFO
, BasicTypeInfo.INT_TYPE_INFO
, BasicTypeInfo.STRING_TYPE_INFO};
TableSink jdbcSink = JDBCAppendTableSink
.builder()
.setDrivername("ru.yandex.clickhouse.ClickHouseDriver")
.setDBUrl("jdbc:clickhouse://localhost:8123")
.setQuery("insert into student_local(id, name, password, age, date) values(?, ?, ?, ?, ?)")
.setParameterTypes(fieldTypes)
.setBatchSize(15)
.build();
tableEnv.registerTableSink(targetTable
,new String[]{"id","name", "password", "age", "date"},
new TypeInformation[]{Types.INT(), Types.STRING()
, Types.STRING(), Types.INT(), Types.STRING()}, jdbcSink);
result.insertInto(targetTable);
env.execute("Flink add sink");
|