ClickHouse在集群中的数据分布是非常灵活的,例如可以将不同的拓扑结合在一个集群中,使用共享配置等管理多个逻辑集群。
分布式拓扑由两个主要属性定义,这两个主要属性对接两个主要的集群特征:可伸缩性和可靠性。
可伸缩性由数据分片或分段(shard/segment)保证。
可靠性是由数据复制(replication)保证。
数据分片和复制是完全独立的。ClickHouse天然支持分片,而复制严重依赖于Zookeeper,用于通知副本server状态变更。
ClickHouse可以在没有复制的情况下运行,但是即使现在没用到复制,提前配置好也是有意义的。
原因有二:
1.即使现在不使用复制,之后也有可能需要复制。
2.对复制表的插入由Zookeeper确认,跟踪最后100个插入块的校验和,以避免重复,如果检查到之前已经插入过同样的数据则会悄悄丢弃这部分的插入。
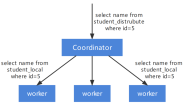
分布式表(Distributed tables):
分布式表用于使用一张表访问位于不同服务器的表(数据分片)。分布式表由“分布式”引擎定义,实际上是分片表上的接口或视图。你可以简单的理解为
它就是一个视图,并不存储数据,会从各个不同的shard中汇总数据。

这里的“集群”(cluster)指的是在ClickHouse配置文件中的集群拓扑定义,它定义了数据如何在不同节点间分布。
shard table必须存在并且在每个节点具有相同的结构。可以同时在一个系统中定义不同的拓扑结构,例如:
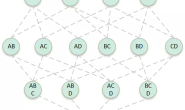
(segmented):每个集群节点都存储数据的一部分。
(segmented mirrored):两个(或更多)集群中的节点组成分片,每个数据段存储在分片的所有节点处。
(cross segmented):每个节点存储两个或更多的分片,每个分片存储在两个或更多的节点上。
(single server):数据位于单个服务器上,但可以通过分布式接口从每个节点访问。
我们来看两个节点上不同拓扑的两个简单例子。

举个例子,假定你有6个nodes:
replcated:
1=2=3=4=5=6
every shard has the same copy of the table. Works for small tables
segmented:
1,2,3,4,5,6 (all different)
segmented_mirrored:
1=4,2=5,3=6 (or in a different order)
集群配置可以即时更新。所以如果新的节点被添加到分布式表中,不需要重新启动服务器。
在一个ClickHouse系统内部,可以使用不同的集群,例如一些表可以归类到没有复制的shard,另外一些归类到存在复制的shard等。另外,可以在“子集群”存储一些数据,但是可以通过全局分布表访问它们。
可以把分布式表视为一个接口。建议进行客户端分段,并将数据插入到ClickHouse节点上的本地分片表中。但是也可以直接插入到分布式表中。在这种情况下,ClickHouse在分片键上使用散列函数分配数据。
所以如果有一个单节点表需要被扩展到多个服务器,过程如下:
1.在新服务器上创建分片表
2.必要时重新分配数据(手动更好,尽管ClickHouse也支持重新分片)
3.定义群集配置并将其放置在每个ClickHouse节点上
4.创建一个分布式表来访问来自多个分片的数据
5.群集扩展更容易,因为它只需要在配置文件中添加新的服务器配置就可以了。
复制表:
复制表用于在不同的服务器上存储数据的多个副本。如上所述,复制依赖Zookeeper集群可用。Zookeper由配置文件中的部分引用:

它可以是一个或多个节点部分,每个主机可以解析为一个或多个IP。
为了创建复制表,应该使用Replicated *系列的表引擎。基本的语法如下:ENGINE = ReplicatedMergeTree(”, ‘{replica}’,, (sort columns), 8192)
不同的Zookeeper路径允许支持不同的复制拓扑。由于很难为每个节点的每个表创建一个自定义路径,因此ClickHouse提供了宏替代机制。宏在每个节点的配置文件中定义(为此目的有一个单独的文件是合理的,例如/etc/clickhouse-server/conf.d/macros.xml),并在大括号中引用。
对于复制表宏,在两个地方有用到:
1.Zookeeper中表的znode的路径
2.副本名称具有相同ZooKeeper路径的表将是特定数据分片的副本。插入操作不限定任何副本,ClickHouse接管复制以确保所有副本处于一致状态。一致性不强制插入,复制是异步的。
可以使用不同的Zookeper路径模拟不同的复制拓扑。例如,宏配置文件可能如下所示:

在这个例子中定义了3个宏:
{cluster} – ClickHouse集群的昵称,用于区分不同集群之间的数据。
{分片} – 分片号或符号引用
{副本} – 副本的名称通常是主机名
来看一些设置复制表的例子:
不可变维度(单个节点上保存完整副本)
ENGINE = ReplicatedMergeTree(‘/clickhouse/{cluster}/tables/’, ‘{replica}’,, (sort columns), 8192)
可变维度(单个节点上保存完整副本)
ENGINE = ReplicatedReplacingMergeTree(‘/clickhouse/{cluster}/tables/’, ‘{replica}’,, (sort columns), 8192)
与前面的例子唯一不同的是’Replacing’替换掉’MergeTree’,允许用主键替换数据。
分片表(每个节点都有一个数据子集)
ENGINE = ReplicatedMergeTree(‘/clickhouse/{cluster}/tables//{shard}’, ‘{replica}’,, (sort columns), 8192)
正如你所看到的,设置复制需要首先创建带副本的表。所以建立系统时先考虑它是有意义的。配置完成后,可以在配置级别上执行增加或替换副本,增加复制因子等维护操作。
Plus:
四种复制模式:
非复制表,internal_replication=false。插入到分布式表中的数据被插入到两个本地表中,如果在插入期间没有问题,则两个本地表上的数据保持同步。我们称之为“穷人的复制”,因为复制在网络出现问题的情况下容易发生分歧,没有一个简单的方法来确定哪一个是正确的复制。
复制表,internal_replication=true。插入到分布式表中的数据仅插入到其中一个本地表中,但通过复制机制传输到另一个主机上的表中。因此两个本地表上的数据保持同步。这是推荐的配置。
非复制表,internal_replication=true。数据只被插入到一个本地表中,但没有任何机制可以将它转移到另一个表中。因此,在不同主机上的本地表看到了不同的数据,查询分布式表时会出现非预期的数据。显然,这是配置ClickHouse集群的一种不正确的方法。
复制表,internal_replication=false。数据被插入到两个本地表中,但同时复制表的机制保证重复数据会被删除。数据会从插入的第一个节点复制到其它的节点。其它节点拿到数据后如果发现数据重复,数据会被丢弃。这种情况下,虽然复制保持同步,没有错误发生。但由于不断的重复复制流,会导致写入性能明显的下降。所以这种配置实际应该是避免的,应该使用配置2。
FAQ:
1.distributed表依赖Zookeeper吗?
ClickHouse的复制依赖Zookeeper。非复制的distributed表不要Zookeeper。所以其实可以创建一个distributed表,既不需要复制,也不需要依赖Zookeeper。