自 Google Dataflow 模型被提出以来,流批一体就成为分布式计算引擎最为主流的发展趋势。流批一体意味着计算引擎同时具备流计算的低延迟和批计算的高吞吐高稳定性,提供统一编程接口开发两种场景的应用并保证它们的底层执行逻辑是一致的。对用户来说流批一体很大程度上减少了开发维护的成本,但同时这对计算引擎来说是一个很大的挑战。
作为 Dataflow 模型的最早采用者之一,Apache Flink 在流批一体特性的完成度上在开源项目中是十分领先的。本文将基于社区资料和笔者的经验,介绍 Flink 目前(1.10)流批一体的现状以及未来的发展规划。 相信不少读者都知道,Flink 遵循 Dataflow 模型的理念: 批处理是流处理的特例。不过出于批处理场景的执行效率、资源需求和复杂度各方面的考虑,在 Flink 设计之初流处理应用和批处理应用尽管底层都是流处理,但在编程 API 上是分开的。这允许 Flink 在执行层面仍沿用批处理的优化技术,并简化掉架构移除掉不需要的 watermark、checkpoint 等特性。
在 Flink 架构上,负责物理执行环境的 Runtime 层是统一的流处理,上面分别有独立的 DataStream 和 DataSet 两个 API,两者基于不同的任务类型(Stream Task/Batch Task)和 UDF 接口(Transformation/Operator)。而更上层基于关系代数的 Table API 和 SQL API 虽然表面上是统一的,但实际上编程入口(Environment)是分开的,且内部将流批作业分别翻译到 DataStream API 和 DataSet API 的逻辑也是不一致的。 因此,要实现真正的流批一体,Flink 需完成 Table/SQL API 的和 DataStream/DataSet API 两层的改造,将批处理完全移植到流处理之上,并且需要兼顾作为批处理立身之本的效率和稳定性。目前流批一体也是 Flink 长期目标中很重要一点,流批一体的完成将标志着 Flink 进入 2.x 的新大版本时代。
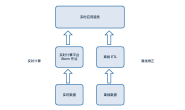
图2. Flink 未来架构
其中 Planner 从 Table/SQL API 层独立出来变为可插拔的模块,而原先的 DataStream/DataSet 层则会简化为只有 DataStream(图 2 中的 StreamTransformation 和 Stream Operator 是 Stream DAG 的主要内容,分别表示 UDF 和执行 UDF 的算子),DataSet API 将被废弃。 Table/SQL API 的改造开始得比较早,截止 1.10 版本发布已经达到阶段性的流批一体目标。然而在 1.7 版本时,Table API 只是作为基于 DataStream/DataSet API 的 lib,并没有得到社区的重点关注。 而当时阿里的 Blink 已经在 Table/SQL 上做了大量的优化,为了合并 Blink 的先进特性到 Flink,阿里的工程师推进社区重构了 Table 模块的架构[5]并将 Table/SQL API 提升为主要编程 API。 自此 Table 层中负责将 SQL/Table API 翻译为 DataStream/DataSet API 的代码被抽象为可插拔的 Table Planner 模块,而 Blink 也将主要的特性以 Blink Planner 的形式贡献给社区,于是有了目前两个 Planner 共存的状态。
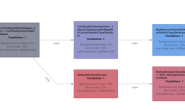
图3. Flink 目前过渡架构
Flink 默认的 Legacy Planner 会将 SQL/Table 程序翻译为 DataStream 或 DataSet 程序,而新的 Blink Planner 则统一翻译为 DataStream 程序。也就是说通过 Blink Planner,Flink Table API 事实上已经实现了流批一体的计算。要了解 Blink Planner 是如何做到的,首先要对 Planner 的工作原理有一定的了解。 Legacy Planner 对于用户逻辑的表示在 Flink 架构中不同层的演变过程如下:
用基于 Calcite 的 SQL parser 解析用户提交的 SQL,将不同类型的 SQL 解析为不同 Operation(比如 DDL 对应 CreateTableOperation,DSL 对应 QueryOperation),并将 AST 以关系代数 Calcite RelNode 的形式表示。
根据用户指定 TableEnvironment 的不同,分别使用不同的翻译途径,将逻辑关系代数节点 RelNode 翻译为 Stream 的 Transformation 或者 Batch 的 Operator Tree。
调用 DataStream 和 DataSet 对应环境的方法将 Transformation 或 Operator Tree 翻译为包含执行环境配置的作业表示,即 StreamGraph 或 Plan。
优化 StreamGraph 和 Plan,并包装为可序列化的 JobGraph。
因为 Batch SQL 与 Streaming SQL 在大部分语法及语义上是一致的,不同点在于 Streaming SQL 另有拓展语法的来支持 Watermark、Time Characteristic 等流处理领域的特性,因此 SQL parser 是 Batch/Stream 共用的。关键点在于对于关系代数 RelNode 的翻译上。
图5. Legacy Planner RelNode
Flink 基于 Calcite RelNode 拓展了自己的 FlinkRelNode,FlinkRelNode 有三个子类 FlinkLogicalRel、DataSetRel 和 DataStreamRel。FlinkLogicalRel 表示逻辑的关系代数节点,比如常见的 Map 函数对应的 FlinkLogicalRel 是 DataStreamCalc。DataSetRel 和 DataStreamRel 则分别表示 FlinkLogicalRel 在批处理和流处理下各自的物理执行计算。 在 SQL 优化过程中,根据编程入口的不同 FlinkLogicalRel 被转化为 DataSetRel 或 DataStreamRel。BatchTableEnvironment 使用 BatchOptimizer 基于 Calcite Rule 的优化,而 StreamTableEnvironment 使用 StreamOptimizer 进行优化。比如 TableScan 这样一个 RelNode,在 Batch 环境下被翻译为 BatchTableSourceScan,在 Stream 环境下被翻译为 StreamTableSourceScan,而这两类物理关系代数节点将可以直接映射到 DataSet 的 Operator 或 DataStream 的 Transformation 上。 上述的方式最大的问题在于 Calcite 的优化规则无法复用,比如对数据源进行过滤器下推的优化,那么需要给 DateSetRel 和 DataStreamRel 分别做一套,而且 DataSet 和 DataStream 层的算子也要分别进行相应的修改,开发维护成本很高,而这也是 Blink Planner 推动流批一体的主要动力。 如上文所说,Blink Planner 做的最重要的一点就是废弃了 DataSet 相关的翻译途径,将 DateSetRel 也移植到 DataStream 之上,那么前提当然是 DataStream 要可以表达 DataSet 的语义。熟悉批处理的同学可能会有疑问: 批处理特有的排序等算子,在 DataStream 中是没有的,这将如何表达? 事实上 Table Planner 广泛采用了动态代码生成,可以绕过 DataStream API 直接翻译至底层的 Transformation 和 StreamOperator 上,并不一定需要 DataStream 有现成的算子,因此使用 Blink Planner 的 Table API 与 DataStream API 的关系更多是并列的关系。这也是 FLIP-32[5] 所提到的解耦 Table API 和 DataStream/DataSet API 的意思:
Decouple table programs from DataStream/DataSet API
Table 改造完成后整个 API 架构如下,这也是目前 1.10 版本已经实现的架构:
事实上,早前版本的 DataStream 对批作业的支持并不是太好,为了支持 Blink Planner 的 Batch on Stream,DataStream 方面也先做了不少的优化。这些优化是对于 Table API 是必要的,因此在 Blink Planner 合并到 Flink master 的前置工作,这将和 DataStream 还未完成的改进一起放在下文分析。 另外虽然 Blink Planner 在计算上是流批一体的,但 Flink Table API 的 TableSource 和 TableSink 仍是流批分离的,这意味着目前绝大数批处理场景的基于 BatchTableSource/BatchTableSink 的 Table 无法很好地跟流批一体的计算合作,这将在 FLIP-95[9] 中处理。 在 DataStream API 方面,虽然目前的 DataStream API 已经可以支持有界数据流,但这个支持并不完整且效率上比起 DataSet API 仍有差距。为了实现完全的流批一体,Flink 社区准备在 DataStream 引入 BoundedStream 的概念来表示有界的数据流,完全从各种意义上代替 DataSet。 BoundedStream 将是 DataStream 的特例,同样使用 Transformation 和 StreamOperator,且同时需要继承 DataSet 的批处理优化。这些优化可以分为 Task 线程模式、调度策略及容错和计算模型及算法这几部分。 批处理业务场景通常更重视高吞吐,出于这点考虑,Batch Task 是 pull-based 的,方便 Task 批量拉取数据。Task 启动后会主动通过 DataSet 的 Source API InputFormat 来读取外部数据源,每个 Task 同时只读取和处理一个 Split。 相比之下,一般流处理业务场景则更注重延迟,因此 Stream Task 是 push-based 的。 DataStream 的 Source API SourceFunction 会被独立的 Source Thread 执行,并一直读取外部数据,源源不断地将数据 push 给 Stream Task。每个 Source Thread 可以并发读取一个到多个 Split/Partition/Shard。
图7. Stream/Batch 线程模型(图来源 Flink Forward)
为了解决 Task 线程模型上的差异,Flink 社区计划重构 Source API 来统一不同外部存储和业务场景下的 Task 线程模型。总体的思路是新增一套新的 Source API,可以支持多种线程模型,覆盖流批两种业务需求,具体可见 FLIP-27[6] 或笔者早前的一篇博客[7]。目前 FLIP-27 仍处于初步的开发阶段。 众所周知,批处理作业和流处理作业在 Task 调度上是很不同的。批处理作业的多个 Task 并不需要同时在线,可以根据依赖关系先调度一批 Task,等它们结束后再运行另一批。 相反地,流作业的所有 Task 需要在作业启动的时候就全部被调度,然后才可以开始处理数据。前一种调度策略通常称为懒调度(Lazy Scheduling),后一种通常称为激进调度(Eager Scheduling)。为了实现流批一体,Flink 需要在 StreamGraph 中同时支持这两种调度模式,也就是说新增懒调度。 随调度而来的问题还有容错,这并不难理解,因为 Task 出现错误后需要重新调度来恢复。而懒调度的一大特点是,Task 计算的中间结果需要保存在某个高可用的存储中,然后下个 Task 启动后才能去获取。 而在 1.9 版本以前,Flink 并没有持久化中间结果。这就导致了如果该 TaskManager 崩溃,中间结果会丢失,整个作业需要从头读取数据或者从 checkpoint 来恢复。 这对于实时流处理来说是很正常的,然而批处理作业并没有 checkpoint 这个概念,批处理通常依赖中间结果的持久化来减小需要重算的 Task 范围,因此 Flink 社区引入了可插拔的 Shuffle Service 来提供 Suffle 数据的持久化以支持细粒度的容错恢复,具体可见 FLIP-31[8]。 与 Table API 相似,同一种计算在流处理和批处理中的算法可能是不同的。典型的一个例子是 Join: 它在流处理中表现为两个流的元素的持续关联,任何一方的有新的输入都需要跟另外一方的全部元素进行关联操作,也就是最基础的 Nested-Loop Join;而在批处理中,Flink 可以将它优化为 Hash Join,即先读取一方的全部数据构建 Hash Table,再读取另外一方进行和 Hash Table 进行关联(见图8)。
这种差异性本质是算子在数据集有界的情况下的优化。拓展来看,数据集是否有界是 Flink 在判断算子如何执行时的一种优化参数,这也印证了批处理是流处理的特例的理念。因此从编程接口上看,BoundedStream 作为 DataStream 的子类,基于输入的有界性可以提供如下优化:
提供只可以应用于有界数据流的算子,比如 sort。
此外,批处理还有个特点是不需要在计算时输出中间结果,只要在结束时输出最终结果,这很大程度上避免了处理多个中间结果的复杂性。因此,BoundedStream 还会支持非增量(non-incremental)执行模式。这主要会作用于与 Time Charateritic 相关的算子:
Processing Time Timer 将被屏蔽。
Watermark 的提取算法不再生效,Watermark 直接从开始时的 -∞ 跳到结束时的 +∞。
基于批处理是流处理的特例的理念,用流处理表达批处理在语义上是完全可行的,而流批一体的难点在于批处理场景作为特殊场景的优化。对 Flink 而言,难点主要体现批处理作业在 Task 线程模型、调度策略和计算模型及算法的差异性上。目前 Flink 已经在偏声明式的 Table/SQL API 上实现了流批一体,而更底层偏过程式的 DataStream API 也将在 Flink 2.0 实现流批一体。 Tips: 原版文章及详细参考资料请见下方原文链接~
原文链接:
http://www.whitewood.me/2020/03/30/Flink-流批一体的实践与探索/
作者介绍:


 图2. Flink 未来架构
图2. Flink 未来架构 图3. Flink 目前过渡架构
图3. Flink 目前过渡架构