源码解析 | 万字长文详解 Flink 中的 CopyOnWriteStateTable

现如今想阅读 HashMap 源码实际上比较简单,因为网上一大堆博客去分析 HashMap 和 ConcurrentHashMap。而本文是全网首篇详细分析 CopyOnWriteStateTable 源码的博客,阅读复杂集合类源码的过程是相当有挑战的,笔者在刚开始阅读也遇到很多疑问,最后一一解决了。本文有一万两千多字加不少的配图,实属不易。
详细阅读完本文,无论是针对面试还是开阔视野一定会对大家有帮助的。
声明:笔者的源码分析都是基于 flink-1.9.0 release 分支,其实阅读源码不用非常在意版本的问题,各版本的主要流程基本都是类似的。如果熟悉了某个版本的源码,之后新版本有变化,我们重点看一下变化之处即可。
本文主要讲述 Flink 中 CopyOnWriteStateTable 相关的知识,当使用 MemoryStateBackend 和 FsStateBackend 时,默认情况下会将状态数据保存到 CopyOnWriteStateTable 中。CopyOnWriteStateTable 中保存多个 KeyGroup 的状态,每个 KeyGroup 对应一个 CopyOnWriteStateMap。
CopyOnWriteStateMap 是一个类似于 HashMap 的结构,但支持了两个非常有意思的功能:
-
1、hash 结构为了保证读写数据的高性能,都需要有扩容策略,CopyOnWriteStateMap 的扩容策略是一个渐进式 rehash 的策略,即:不是一下子将数据全迁移的新的 hash 表,而是慢慢去迁移数据到新的 hash 表中。
-
2、Checkpoint 时 CopyOnWriteStateMap 支持异步快照,即:Checkpoint 时可以在做快照的同时,仍然对 CopyOnWriteStateMap 中数据进行修改。问题来了:数据修改了,怎么保证快照数据的准确性呢?
了解 Redis 的同学应该知道 Redis 也是一个大的 hash 结构,扩容策略也是渐进式 rehash。Redis 的 RDB 在持久化数据的过程中同时也是对外服务的,对外服务意味着数据可能被修改,那么 RDB 如何保证持久化好的数据一定是正确的呢?
举个例子:17 点00分00秒 RDB 开始持久化数据,过了 1 秒 Redis 中某条数据被修改了,过了一分钟 RDB 才持久化结束。RDB 预期的持久化结果应该是 17 点00分00秒那一刻 Redis 的完整快照,请问持久化过程中那些修改操作是否会影响 Redis 的快照。答:当然可以做到不影响。
Flink 在 Checkpoint 时的快照与 Redis 类似,都是想在快照时依然对外提供服务,减少服务停顿时间。Flink 具体如何实现上述功能的呢?带着问题详细阅读下文。
1.StateTable 简介
StateTable 有两个实现:CopyOnWriteStateTable 和 NestedMapsStateTable。
-
CopyOnWriteStateTable 属于 Flink 自己定制化的数据结构,Checkpoint 时支持异步 Snapshot。
-
NestedMapsStateTable 直接嵌套 Java 的两层 HashMap 来存储数据,Checkpoint 时需要同步快照。
下面详细介绍 CopyOnWriteStateTable。
2.CopyOnWriteStateTable
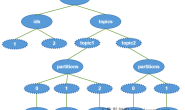
StateTable 中持有 StateMap[] keyGroupedStateMaps 真正的存储数据。StateTable 会为每个 KeyGroup 的数据初始化一个 StateMap 来对 KeyGroup 做数据隔离。对状态进行操作时,StateTable 会先根据 key 计算对应的 KeyGroup,拿到相应的 StateMap,才能对状态进行操作。
CopyOnWriteStateTable 中使用 CopyOnWriteStateMap 存储数据,这里主要介绍 CopyOnWriteStateMap 的实现。CopyOnWriteStateMap 中就是一个数组 + 链表构成的 hash 表。
CopyOnWriteStateMap 中元素类型都是是:StateMapEntry。hash 表的第一层先是一个 StateMapEntry 类型的数组,即:StateMapEntry[]。在 StateMapEntry 类中有个 StateMapEntry next 指针构成链表。
CopyOnWriteStateMap 相比普通的 hash 表,有以下几点需要重点关注:
-
CopyOnWriteStateMap 的扩容策略是渐进式 rehash,而不是一下子扩容完
-
为了支持异步的 Snapshot,需要将 Snapshot 时 StateMap 的快照保存下来,具体的保存策略怎么实现的?
-
为了支持 CopyOnWrite 功能,所以在修改数据时,要进行一系列 copy 的操作,不能修改原始数据,否则会影响 Snapshot。
-
Snapshot 异步快照流程及 Snapshot 完成时,如何 release 掉旧版本数据?
3.CopyOnWriteStateMap 的渐进式 rehash 策略
渐进式 rehash 策略表示 CopyOnWriteStateMap 中当前有一个 hash 表对外服务,但是当前 hash 表中元素太多需要扩容了,需要将数据迁移到一个容量更大的 hash 表中。
Java 的 HashMap 在扩容时会一下子将旧 hash 表中所有数据都移动到大 hash 表中,这样的策略存在的问题是如果 HashMap 当前存储了 1 G 的数据,那么瞬间需要将 1 G 的数据迁移完,可能会比较耗时。而 CopyOnWriteStateMap 在扩容时,不会一下子将数据全部迁移完,而是在每次操作 CopyOnWriteStateMap 时,慢慢去迁移数据到大的 hash 表中。
例如:可以在每次 get、put 操作时,迁移 4 条数据到大 hash 表中,这样经过一段时间的 get 和 put 操作,所有的数据就能迁移完成。所以渐进式 rehash 策略,会分很多次将所有的数据迁移到新的 hash 表中。
3.1 扩容简述
在内存中有两个 hash 表,一个是 primaryTable 作为主桶,一个是 rehashTable 作为扩容期间用的桶。初始阶段只有 primaryTable,当 primaryTable 中元素个数大于设定的阈值时,就要开始扩容。
扩容过程:申请一个相比 primaryTable 容量大一倍的 hash 表保存到 rehashTable 中,慢慢地将 primaryTable 中的元素迁移到 rehashTable 中。对应到源码中:putEntry 方法中判断 size() > threshold 时,会调用 doubleCapacity 方法申请新的 hash 表赋值给 rehashTable。
如下图所示 primaryTable 中桶的个数为 4,rehashTable 中桶的个数为 8。

扩容时 primaryTable 中 0 位置上的元素会迁移到 rehashTable 的 0 和 4 位置上,同理 primaryTable 中 1 位置上的元素会迁移到 rehashTable 的 1 和 5 位置上。
3.2 选择 Table 的策略
假设 primaryTable 中 0 桶的数据已经迁移到 rehashTable 桶了,那么之后无论是 put 还是 get 操作 0 桶的数据,那么都会去操作 rehashTable。而 1、2、3 桶还未迁移,所以 1、2、3 桶还需要操作 primaryTable 桶。对应到源码中会有一个选桶的操作,选择到底使用 primaryTable 还是 rehashTable。
源码实现如下所示:
首先通过 int curIndex = hashCode & (primaryTable.length – 1); 计算当前 hashCode 应该分到 primaryTable 的哪个桶中。
rehashIndex 用来标记当前 rehash 迁移的进度,即:rehashIndex 之前的数据已经从 primaryTable 迁移到 rehashTable 桶中。假设 rehashIndex = 1,表示 primaryTable 1 桶之前的数据全部迁移完成了,即:0 桶数据全部迁移完了。
策略:大于等于 rehashIndex 的桶还未迁移,应该去 primaryTable 中去查找。小于 rehashIndex 的桶已经迁移完成,应该去 incrementalRehashTable 中去查找。
3.3 迁移过程
每次有 get、put、containsKey、remove 操作时,都会调用 computeHashForOperationAndDoIncrementalRehash 方法触发迁移操作。
computeHashForOperationAndDoIncrementalRehash 方法作用:
-
检测是否处于 rehash 中,如果正在 rehash 就会调用 incrementalRehash 迁移一波数据
-
计算 key 和 namespace 对应的 hashCode
重点关注 incrementalRehash 方法实现:
incrementalRehash 方法中第一层 while 循环用于控制每次迁移的最小元素个数。然后遍历 oldMap 的第 rhIdx 个桶,e 指向当前遍历的元素,每次 e 都指向 e.next,e 不为空,表示当前桶中还有元素未遍历,需要继续遍历。每次迁移必须保证,整个桶被迁移完,不能是某个桶迁移到一半。
迁移过程中,将当前元素 e 重新计算 hash 值,插入到 newMap 相应桶的头部(头插法)。其中 e.entryVersion < requiredVersion 时,需要创建一个新的 Entry,这里是为了支持 CopyOnWrite 功能,下面会介绍。
4.StateMap 的 Snapshot 策略
StateMap 的 Snapshot 策略是指:为了支持异步的 Snapshot,需要将 Snapshot 时 StateMap 的快照保存下来。
传统的方法就是将 StateMap 的全量数据在内存中深拷贝一份,然后拷贝的这一份数据去慢慢做快照,原始的数据可以对外服务。但是深拷贝需要拷贝所有的真实数据,所以效率会非常低。为了提高效率,Flink 只是对数据进行了浅拷贝。
4.1 浅拷贝原理分析
浅拷贝就是只拷贝引用,不拷贝数据。
假如 StateMap 没有处于扩容中,Snapshot 流程相对比较简单,创建一个新的 snapshotData,直接将 primaryTable 的数据拷贝到 snapshotData 中即可。

如图所示,对于浅拷贝可以理解为两个 Table 的 0 号桶中都引用的同一个链表,也就是将 snapshotData 指向图中的 Entry a 即可。其他桶的浅拷贝也是类似,就不一一画图了。
假如 StateMap 当前处于扩容中,Snapshot 流程相对比较繁琐,创建一个新的 snapshotData,需要将 primaryTable 和 rehashTable 的数据都拷贝到 snapshotData 中。

如图所示,将原始两个 Table 数据拷贝到 snapshotData 中,但是 snapshotData 数组的长度并不是 primaryTable 的长度 + rehashTable 的长度。而是分别计算 primaryTable 和 rehashTable 中有几个桶中有数据。例如上图案例所示,primaryTable 中有 3 个桶中有元素,rehashTable 中有 2 个桶中有元素,所以snapshotData 的桶数量为 5 即可,没必要 4 + 8 = 12 个桶。
上图中也是省略了 Entry,Entry 引用的浅拷贝与之前没有扩容的情况类似。
4.2 浅拷贝源码详解
首先调用 CopyOnWriteStateTable 的 stateSnapshot 方法对整个 StateTable 进行快照。stateSnapshot 方法会创建 CopyOnWriteStateTableSnapshot,CopyOnWriteStateTableSnapshot 的构造器中会调用 CopyOnWriteStateTable 的 getStateMapSnapshotList 方法。
getStateMapSnapshotList 方法源码如下所示:
CopyOnWriteStateTable 中为每个 KeyGroup 维护了一个 StateMap 到 keyGroupedStateMaps 中,getStateMapSnapshotList 方法会调用所有 CopyOnWriteStateMap 的 stateSnapshot 方法。
CopyOnWriteStateMap 的 stateSnapshot 方法相关源码如下所示:
CopyOnWriteStateMap 的 stateSnapshot 方法会创建 CopyOnWriteStateMapSnapshot,CopyOnWriteStateMapSnapshot 的构造器中会调用 StateMap 的 snapshotMapArrays 方法对 StateMap 的数据进行浅拷贝生成 snapshotData。且将当前的 StateMap 版本到 snapshotVersion 中。
StateMap 的 snapshotMapArrays 方法对浅拷贝原理进行了代码实现,代码如下所示:
CopyOnWriteStateMap 中三个比较重要的属性:
-
stateMapVersion:表示当前 StateMap 的版本,每次 Snapshot 时版本号加一
-
snapshotVersions:存放所有正在进行中的 snapshot 的版本号(因为可能存在多个同时进行的 Snapshot)
-
highestRequiredSnapshotVersion:表示正在进行中的那些 snapshot 的最大版本号,如果当前没有正在进行中的 Snapshot,那么赋值为 0
snapshotMapArrays 方法第一步按照上述规则更新这三个属性,第二步将现在 primaryTable 和 rehashTable 的元素浅拷贝一份到 copy 数组中。
注:copy 数组的长度与上述原理分析不完全一致,原理分析时应该是 copiedArraySize = totalMapIndexSize;实际上 copiedArraySize = Math.max(totalMapIndexSize, size())。
源码注释写到:理论上 totalMapIndexSize 就够了,这里考虑 size 主要是为了兼容 StateMap 的 TransformedSnapshotIterator 功能。
5.CopyOnWrite 实现原理
上一部分得出结论,每次 Snapshot 时仅仅是浅拷贝一份,所以 Snapshot 和 StateMap 共同引用真实的数据。假如 Snapshot 还没将数据 flush 到磁盘,但是 StateMap 中对数据进行了修改,那么 Snapshot 最后 flush 的数据就是错误的。Snapshot 的目标是:将 Snapshot 快照中原始的数据刷到磁盘,既然叫快照,所以不允许被修改。
5.1 CopyOnWrite 原理简述
那 StateMap 如何来保证修改数据的时候,不会修改 Snapshot 的数据呢?其实原理很简单:StateMap 和 Snapshot 共享了一大堆数据,既然 Snapshot 要求数据不能修改,那么 StateMap 在修改某条数据时可以将这条数据复制一份产生一个副本,所以 Snapshot 和 StateMap 就会各自拥有自己的副本,所以 StateMap 对数据的修改就不会影响 Snapshot 的快照。
当然为了节省内存和提高效率,StateMap 只会拷贝那些要改变的数据,尽量多的实现共享,不能实现共享的数据只能 Copy 一份再修改了,这就是类名用 CopyOnWrite 修饰的原因。
5.2 CopyOnWrite 原理详解
上一部分 Snapshot 时,仅仅对 Table 做了一份浅拷贝,而且可以看到拷贝前后,桶内的数据不变,且桶跟桶之间是没有交集的,所以这里的原理详解主要就分析一个桶中的链表如何实现 CopyOnWrite。
■ 5.2.1 修改链表头部节点的场景

如上图所示,primaryTable 和 snapshotTable 的 0 号桶都指向 Entry a,假设现在应用层要修改 Entry a 的数据,整体流程:
-
深拷贝一个 Entry a 对象为 Entry a copy
-
将 Entry a copy 放到 primaryTable 的链表中,且 next 指向 Entry b
-
应用层修改 Entry a copy 的 data,将 data1 修改为设定的 data2
这里 Entry b 和 c 没有修改,所以不用拷贝,属于 primaryTable 和 snapshotTable 共享的。
这里就引出了 CopyOnWriteStateMap 的设计目标(自己的理解,并不是官方观点):在保证 Snapshot 数据正确性的前提下,尽量的少拷贝数据提高性能。
■ 5.2.2 修改链表中间节点的场景

如上图所示,primaryTable 和 snapshotTable 的 0 号桶都指向 Entry a,假设现在应用层要修改 Entry b 的数据,整体流程:
-
深拷贝一个 Entry b 对象为 Entry b copy
-
将 Entry b copy 串在 primaryTable 的链表中,且 next 指向 Entry c
-
应用层修改 Entry b copy 的 data,将 data 修改为设定的 data2
但是上述流程成立吗?如上图所示 Entry a 和 c 是 primaryTable 和 snapshotTable 共享的。每个 Entry 只有一个 next 指针,所以 Entry a 可以同时指向 Entry b 和 b copy 吗?肯定是不可以的,所以 Entry a 不可以共享。下图是正确流程。

如下图所示,在修改 Entry b 时,不仅仅要将 Entry b 拷贝一份,而且还要将链表中 Entry b 之前的 Entry 必须全部 copy 一份,这样才能保证在满足正确性的前提下修改 Entry b,毕竟正确性是第一位。
正确整体流程:
-
深拷贝 Entry a 和 b 对象为 Entry a copy 和 b copy
-
将 Entry a copy 和 b copy 串在 primaryTable 的链表中,且 Entry b 的 next 指向 Entry c
-
应用层修改 Entry b copy 的 data,将 data 修改为设定的 data2
总结:假设要修改 Entry b,那么要将 Entry b 以及链表中 Entry b 之前的 Entry 必须全部 copy 一份,Entry b 之后的 Entry 可以共享。
■ 5.2.3 插入新数据的场景

如上图所示是插入新数据的场景,会使用头插法插入 Entry d,头插法不需要拷贝原始链表的任何数据,只需要插入最新的数据到链表头部即可。这样 primaryTable 可以访问到插入的数据,且不影响 SnapshotData 访问原始快照的数据。
注:这里必须是插入新数据的场景,对于 Map 类型,插入旧数据对应的可能是修改操作
■ 5.2.4 链表头部有新节点再修改链表中间节点的场景

如上图所示是链表头部有新节点 Entry d 再修改 Entry b 的场景,此时正确的流程是:
-
深拷贝 Entry a 和 b 对象为 Entry a copy 和 b copy
-
将 Entry a copy 和 b copy 串在 Entry d 的链表中,且 Entry b 的 next 指向 Entry c
-
应用层修改 Entry b copy 的 data,将 data 修改为设定的 data2
之前说过要修改 Entry b 需要将 Entry b 之前的 Entry 全部 copy 一份,但是此时并不需要对 Entry d 进行 copy。之前 copy 是因为 Entry b 之前的元素有被 snapshotData 引用,但是这里 Entry d 并不被 snapshotData 引用,只有 primaryTable 只有 Entry d,所以不需要 copy。
修改 Entry b 时,Entry b 之前的 Entry 哪些需要 copy,哪些不需要 copy,具体如何区分会在后续的源码环节详细介绍。
■ 5.2.5 get 链表中间节点的场景
理论来讲,访问中间节点的场景数据数据是非常安全的。

如下图所示 Flink 应用层通过 primaryTable 访问 Entry b,理论来讲只是读取的场景就不需要 copy 副本了。因为之前 copy 副本都是因为应用层修改了数据,为了保证 Snapshot 数据的不可变特性,所以专门 copy 一个副本让 primaryTable 去修改。但神奇的是 CopyOnWriteStateMap 在 get 操作时,也需要将 Entry b 以及 Entry b 之前的所有 Entry 拷贝一个副本。
为什么呢?虽然是 get 访问操作,但是应用层拿到了 Entry b 中的 data 对象,万一应用层修改了 data 对象里的属性怎么办呢?例如 Entry 中的 data 是 Person 对象,Person 对象可能有一些 setter 方法,可以修改其 name 和 age。如果应用层修改了 name 或 age,那么在 Snapshot 的过程中,还是出现了数据修改的情况。
所以 CopyOnWriteStateMap 把 get 操作跟 put 操作同等对待,无论是 get 还是 put 都需要将 Entry 及其之前的 Entry copy 一份。
■ 5.2.6 remove 数据的场景
需要区分两种 case:remove 的 Entry 是链表头节点;remove 的 Entry 不是链表头节点。
Case1:remove 的 Entry 是链表头节点的场景比较简单,将桶直接指向 Entry a 的 next Entry b 即可。

Case 2:remove 的 Entry 不是链表头节点,需要将 Entry b 之前的所有 Entry 拷贝一份(新插入的 Entry 不需要拷贝),且 Entry b 前一个节点的副本直接指向 Entry b 的下一个节点。具体为什么 Entry a 需要拷贝一份与 put 和 get 操作类似,因为 Entry a 的 next 指针没办法指向两个节点,所以 primaryTable 和 snapshotTable 要有各自的头结点。

■ 5.2.7 COW 原理小结
上述 case 基本覆盖到了各种场景,这里做一个总结:
-
插入新的 Entry 使用头插法插入到链表中
-
假设要修改 Entry b,那么要将 Entry b 以及链表中 Entry b 之前的 Entry 必须全部 copy 一份(新插入的数据不需要拷贝),Entry b 之后的 Entry 可以共享
-
访问 Entry b 的场景与修改 Entry b 的场景类似
-
假如修改或访问的数据是 copy 后的数据,那么实际上不需要再 copy 了,因为 copy 后的数据已经保证是 primaryTable 独占的数据,不与 Snapshot 共享
-
remove 数据的场景,分为两种 case:
-
如果 remove 的 Entry 是链表头节点,将桶直接指向头结点的 next 节点即可。
-
如果 remove 的 Entry 不是链表头节点,需要将目标 Entry 之前的所有 Entry 拷贝一份,且目标 Entry 前一个节点的副本直接指向目标 Entry 的下一个节点。当然如果前继节点已经是新版本了,则不需要拷贝,直接修改前继 Entry 的 next 指针即可。
5.3 CopyOnWriteStateMap 各种操作源码详解
■ 5.3.1 CopyOnWriteStateMap 介绍
CopyOnWriteStateMap 类用于存储数据,支持了 CopyOnWrite 的功能,先介绍 CopyOnWriteStateMap 中一些相对重要的字段,相关源码如下所示(重点看一下每个字段的注释):
其中 primaryTable 字段是真正存储数据的 hash 表,primaryTable 是 StateMapEntry 类型的数据,StateMapEntry 用于存储 StateMap 中的一条数据,下面介绍 StateMapEntry。
■ 5.3.2 StateMapEntry
StateMapEntry 是 CopyOnWriteStateMap 中真正存储数据的实体。在 Java 的 HashMap 中也是将数据封装在 Entry 中,HashMap 的 Entry 源码如下所示:
HashMap 中的静态内部类 Node 实现 Map.Entry,类中有四个字段:hash、key、value、next。key 和 value 不同解释,hash 表示当前 key 对应的 hash 值,next 指向当前桶中下一个 Node。
HashMap 在 get(key) 查找数据流程:
-
根据 key 计算 hash 值,定位到具体的桶
-
遍历当前桶的一个个 Entry,先比较 hash 值是否相同,在比较 key 是否相同(使用 equals 判断 key 是否相同)
-
如果 hash 值和 key 的 equals 方法都能匹配,表示找到了对应的 Entry,返回 Entry 中的 value 即可
StateMapEntry 源码如下所示:
StateMapEntry 与 HashMap 的 Entry 相似度较高,其他 key、hash、next 这三个属性完全相同,StateMapEntry 中的 state 表示 HashMap 中的 value,即:具体存储的数据。
StateMapEntry 相比 HashMap 的 Entry,多了三个字段:
-
namespace:namespace 是 Flink 中的概念,用于区分不同的 Window,在 StateMapEntry 中 key 和 namespace 组合起来作为共同的主键,state 作为 value
-
entryVersion:表示创建 entry 时的版本号
-
stateVersion:表示当前 StateMapEntry 中 state (数据)更新时的版本号
由于 key 和 namespace 共同作为主键,因此在 CopyOnWriteStateMap 的 get 或 put 操作中,判断是否找到了匹配的 Entry,不仅要判断 hash 值,还要通过 equals 方法对 key 和 namespace 进行判断。三个参数都校验通过才能表示找到了相应的 Entry。这一点是与 HashMap 区别较大的,要注意理解。
■ 5.3.3 插入新数据源码流程
CopyOnWriteStateMap 类的 put 方法如下所示:
put 方法直接调用 putEntry 方法,putEntry 用于找到对应的 Entry,putEntry 包括了修改数据或插入新数据的场景。找到 Entry 后,将 value set 到 Entry 中。
putEntry 方法源码如下所示:
putEntry 方法首先会计算当前 key 和 namespace 对应的 hash 值,使用 selectActiveTable 选择使用 primaryTable 或 incrementalRehashTable,然后计算当前元素对应桶的 index。
这里注意,普通的 HashMap 结构有一个 Key 一个 value。而这里 key 和 namespace 的组合当做 Map 的 key,value 仍然是原来的 value。
遍历当前桶中链表的一个个 Entry,如果通过 hash 值、 key 和 namespace 的 equals 方法进行匹配,如果匹配成功,表示找到了对应的 Entry,则认为是修改数据。
如果遍历完当前桶中链表的所有元素还没找到匹配的 Entry,说明是插入一条新数据,则执行 addNewStateMapEntry 方法往链表头部插入一个新的 Entry 返回(头插法)。
■ 5.3.4 修改数据源码流程
在 putEntry 中,修改数据场景的源码如下所示:
这里是上一部分插入新数据的部分源码,现在重点讲述修改数据的过程。如果根据 key 和 namespace 找到了相应的 Entry,则认为是对老数据的修改,走相应的修改逻辑。然后判断当前 Entry 的 entryVersion 是否小于 highestRequiredSnapshotVersion。
entryVersion 表示 entry 创建时的版本号,highestRequiredSnapshotVersion 表示正在进行中的那些 snapshot 的最大版本号。
-
entryVersion 小于 highestRequiredSnapshotVersion,说明 Entry 创建时的版本小于当前某些 Snapshot 的版本号,即:当前 Entry 是旧版本的数据,当前 Entry 被其他 Snapshot 持有。为了保证 Snapshot 的数据正确性,这里必须为 e 创建新的副本,且 e 之前的某些元素也需要 copy 副本,handleChainedEntryCopyOnWrite 方法将会进行相应的 copy 操作,并返回 e 的新副本。最后将 e 的副本返回给上层,进行数据的修改操作。
-
反之,entryVersion >= highestRequiredSnapshotVersion,说明当前 Entry 创建时的版本比所有 Snapshot 的版本高。Snapshot 不可能引用高版本的数据,所以当前 Entry 是新版本的数据不被任何 Snapshot 持有。此时 e 是新的 Entry,不存在共享问题,所以直接修改当前 Entry 即可,所以返回当前 e。
handleChainedEntryCopyOnWrite 方法的作用:为 Entry e 创建新的副本,且链表中 Entry e 之前某些元素也需要 copy 副本,最后返回 e 的副本。
那哪些元素应该拷贝,哪些元素不应该拷贝呢?Snapshot 之后新创建的 Entry 就不需要再拷贝了,Snapshot 之前创建的 Entry 会被 Snapshot 引用所以需要再拷贝。
handleChainedEntryCopyOnWrite 的源码如下所示:
从源码可以看到,,从头结点到要修改的 Entry 节点依次遍历桶中元素,都是使用 current.entryVersion < highestRequiredSnapshotVersion 来判断当前节点的创建创建时的版本是否低于 highestRequiredSnapshotVersion。
-
如果低于则 current 节点被 Snapshot 引用,所以需要 new 一个新的 Entry,也就是所谓的拷贝一个副本。
-
否则不用拷贝。
在新创建 Entry 时,新 Entry 的 entryVersion 要更新为当前 StateMap 的 version,表示这是一个新版本的 Entry,并没有被 Snapshot 引用。这样之后再要修改该 Entry 时直接修改该 Entry 即可,不需要再拷贝一份副本了。
■ 5.3.5 访问数据源码流程
CopyOnWriteStateMap 类的 get 方法与 putEntry 类似,都是依次遍历相应桶的元素,直到根据 key 和 namespace 找到了相应的 Entry,则返回相应的 Entry。如果遍历完相应桶的所有 Entry,都没有与 key 和 namespace 相匹配的 Entry,则表示 StateMap 中没有指定的元素则返回 null。
如果找到了相应 Entry,为了保证 Snapshot 引用的数据不被修改,所以也要进行拷贝操作。除了拷贝其他源码比较简单与 putEntry 完成类似,所以重点分析找到 Entry 后的相关源码。相关源码如下所示:
一旦 get 当前数据,为了防止应用层修改数据内部的属性值,所以必须保证这是一个最新的 Entry,并更新其 stateVersion。首先检查当前的 State,也就是 value 值是否是旧版本数据:
-
如果 value 是旧版本,则必须深拷贝一个 value
-
否则 value 是新版本,直接返回给应用层
如果 value 值是还区分两种情况:
-
1、如果当前 Entry 是旧版本的,则 Entry 也需要拷贝一份,按照之前分析过的 handleChainedEntryCopyOnWrite 策略拷贝即可
-
2、当前 Entry 是新版本数据,则不需要拷贝,直接修改其 State 即可
case 1 容易理解,如下图所示访问 Entry b 就是 case 1 的场景,需要使用 handleChainedEntryCopyOnWrite 方法对 Entry b 和 a 进行拷贝操作,然后再对 Entry b 的 value 对象进行一次深拷贝,所以 Entry b 和 b copy 不会共享 data 对象。
虽然 Entry a 也拷贝了一份生成 Entry a copy,但是 Entry a 中的 value 对象并没有深拷贝一份,而是共享 data1 对象。get Entry b 后 Entry a 和 a copy 引用 data 1 的图示用下图会更形象一些,即:Entry a 和 a copy 的 state 会共同引用 data1 对象。对于修改 Entry a 如果下次再有 get 操作,就会对应上述的 case 2 场景:stateVersion 是老版本,但是 Entry a copy 属于新版本。此时不需要再对 Entry 进行复制操作,只需要对 State 进行一次深拷贝,保证不会将 Entry a 的 State 返回给应用层。

■ 5.3.6 remove 数据源码流程
removeEntry 源码如下所示:
remove 数据的场景,分为两种 case:
-
如果 remove 的 Entry 是链表头节点,将桶直接指向头结点的 next 节点即可。
-
如果 remove 的 Entry 不是链表头节点,需要将目标 Entry 之前的所有 Entry 拷贝一份,且目标 Entry 前一个节点的副本直接指向目标 Entry 的下一个节点。当然如果前继节点已经是新版本了,则不需要拷贝,直接修改前继 Entry 的 next 指针即可。
源码比较清晰加上已经详细分析了 put 和 get 源码,所以 remove 源码直接结合原理看注释即可。
6.Snapshot 流程及完成后的 release 操作
前面已经分析了 CopyOnWriteStateMap 的扩容 rehash 原理和源码、Snapshot 时浅拷贝原理和源码以及CopyOnWrite 实现的原理和源码。
CopyOnWrite 的实现主要为了减少 Checkpoint 同步阶段的停顿时间,将数据的快照过程尽量放到异步流程。下面分析 Snapshot 异步快照流程及 Snapshot 完成后 release 相关操作。
HeapSnapshotStrategy 类的 AsyncSnapshotCallable 匿名内部类的 callInternal 方法中会调用 AbstractStateTableSnapshot 的 writeStateInKeyGroup 方法,并依次将每个 KeyGroupId 当做参数传入。
writeStateInKeyGroup 方法源码如下所示:
writeStateInKeyGroup 方法拿到 KeyGroupId 对应的 CopyOnWriteStateMapSnapshot,然后将 stateMapSnapshot 中的 State 数据进行序列化输出,这一步就会依次遍历 stateMapSnapshot 所有引用的数据序列化输出到外部存储中。序列化完成就可以释放该快照了。
release 最后会调用 CopyOnWriteStateMap 的 releaseSnapshot 方法,releaseSnapshot 方法源码如下所示:
releaseSnapshot 方法将相应的 snapshotVersion 从 snapshotVersions 中 remove,并将 snapshotVersions 的最大值更新到 highestRequiredSnapshotVersion,如果snapshotVersions 为空,则 highestRequiredSnapshotVersion 更新为 0。
有个小疑问:根据之前的流程分析,Snapshot 过程中如果 Flink 应用层发生了大量 get 和 put 操作,那么很多 Entry 和 State 都会出现多个副本。Snapshot 结束后,就应该把那些旧版本的数据清理掉。可是没有看到对旧版本数据进行清理操作呢?
如上图所示,Entry b 和 a 都存在副本,当 Snapshot 结束后,因为新数据在 Entry a copy 和 b copy 中,所以 Entry a 和 b 都应该被清理掉,留着 Entry a copy 和 b copy 即可。但是代码中没有看到去清理 Entry a 和 b。那么会不会出现内存泄漏的问题呢?
其实并不会,Snapshot 结束后 snapshotData 对应的 hash 表不会再被异步快照的线程引用,所以 Entry a 和 b 就会变成不可达对象,会被 JVM 的 GC 回收掉。
7.总结
本文详细介绍了 CopyOnWriteStateTable 的设计原理及相关源码,主要从 rehash 和 CopyOnWrite 两个点进行深入剖析,希望对大家能有所帮助。
本文涉及的 github 仓库,都在 feature/source-code-read-1-9-0 分支,之后也会持续更新:
https://github.com/1996fanrui/flink/tree/feature/source-code-read-1-9-0注释