初识Hadoop、Hive
2016.10.13 20:28
很久没有写随笔了,自打小宝出生后就没有写过新的文章。数次来到博客园,想开始新的学习历程,总是被各种琐事中断。一方面确实是最近的项目工作比较忙,各个集群频繁地上线加多版本的提测,每次到了晚上就感觉很疲惫,另一方面确实是自己对自己最近有些放松,没有持续地学习。很庆幸今天能在一个忙碌的工作日后,开始着手这篇文章。
来到大数据前,我对大数据可以说是一无所知。诸如Hadoop、Hive等名词仅仅处于“听过”的阶段,完全不知道其作用。大数据的概念真的很多,想真正理解必须从实践中慢慢体会,否则则永远只能停留在字面意思。
一、Hadoop
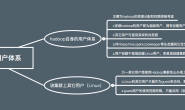
相信大部分人都听过Hadoop,但是都不知道它到底是干什么的,有什么作用。Hadoop其实可以分为两块:HDFS和MapReduce。
HDFS:Hadoop Distributed File System,是一个分布式文件系统,它的主要作用是为海量数据提供存储,并提供“流式“访问文件系统中的数据。存储在HDFS中的数据文件是结构化的,比如日志文件。
MapReduce:看过廖雪峰的Python教程的人应该都对Map和Reduce有一定了解,这里的MapReduce其实就是一样的操作(如果没看过,想了解Map、Reduce过程可以访问《廖雪峰Python教程-map/reduce》)。它主要提供了对海量数据的计算。
二、Hive
在实践中,数据开发工程师们想对数据进行计算就要写一个MapReduce程序,而这显然需要较大的成本,对于那些不擅长开发的人想简单地查询数据更是抬高了较大的门槛。于是Hive就是为了解决这个问题而生的。它将存储在HDFS中的数据文件(例如日志),通过建立一种映射关系映射成一张数据库表,即Hive表。Hive中有一个模块“metastore”,,一般使用mysql,就是专门用来存储该映射后的数据库表的表结构信息,例如表名、字段名、分区、属性(是否外部表、分区表)等,没有具体的数据。业界也称它为”元数据“。然后真实的数据可以通过load data转换为hive表中的数据,或者通过add partition的方式建立数据映射,从而Hive就提供了一种通过SQL语句查询的方式来计算HDFS中的实际数据文件。
当一条Hive SQL语句被执行时,Hive有一套映射工具(metastore,一般存放在mysql、derby中),它会对应地将SQL语句转化为MapReduce任务,把sql中的表、字段映射成HDFS中的文件、列,然后去执行对HDFS原始数据文件的计算。
其实这些内容似乎在所有关于Hadoop、Hive的地方都能看到,字面上理解也并不难。但是如果你是一个真正的初次接触大数据的人的话,我想你会可能也跟我刚开始一样,对它们的理解仅仅是停留在字面。这里举一个例子来解释上面这些字面真正的意思。
比如我有一个存在HDFS中的access.log日志文件,其内容如下:

假如想统计ip为10.165.152.123的登录记录,如果通过MapReduce去做的话,可能的代码实现方法是:首先解析日志文件,每行去查找是否包含“10.165.152.123”,如果是则再通过正则匹配去取出后面的相关内容(Map);然后对每行的结果进行汇总计算(Reduce)。
Hive的做法:
1. 先任意取一条日志,例如10.165.152.123 – – [13/Oct/2016:14:55:06 +0800] “GET /index.html HTTP/1.0” 200 7992 2124,将其中的列映射成字段,如:10.165.152.123对应ip,13/Oct/2016:14:55:06对应time,GET /index.html HTTP/1.0对应method(请求方法),200对应result(返回码),7992对应bytes(字节数),2124对应response_time(响应时间)。
2. 然后相对应地,选定一个数据库(比如znilog)下,创建一张表名为tbl_accesslog的记录字段名、是否分区(比如按date分区)、属性(是否外部表)的hive表。
需要注意的是,hive表的实际存储位置也是在hdfs上,比如这种情况下默认的hdfs路径可能就是/warehouser/znilog.db/tbl_accesslog。这个路径就是内部表(也称管理表)的hdfs存储路径。如果是外部表,用户可以自己设定外部表的location。
3. 对于内部表,我们需要将数据通过load data的方式,将原始数据文件中的数据通过映射的方式,转化为映射后的数据(一般按列存放)存入内部表下。
4. 对于外部表,我们可以直接通过add partition的方式将原始hdfs路径下的数据文件,映射到外部表下。当删除表时,Hive默认存储位置的数据会被删除,但是外部表的数据不会被删除。
5. 这样我们就有了Hive表,以及Hive表包含的元数据信息(存在metastore中,一般是mysql),Hive表中包含转化后的数据信息,我们可以直接通过Hive SQL语句(select * from tbl_accesslog where ip=’10.165.152.123’)来获取我们想要的信息。
转发申明:
本文转自互联网,由小站整理并发布,在于分享相关技术和知识。版权归原作者所有,如有侵权,请联系本站,将在24小时内删除。谢谢

![[Hadoop in Action] 第6章 编程实践](https://www.top8488.top/wp-content/themes/Git-alpha-GiUEQq/timthumb.php?src=https://www.top8488.top/wp-content/themes/Git-alpha-GiUEQq/assets/img/pic/8.jpg&h=110&w=185&q=90&zc=1&ct=1)
![[Hadoop in Action] 第5章 高阶MapReduce](https://www.top8488.top/wp-content/themes/Git-alpha-GiUEQq/timthumb.php?src=https://www.top8488.top/wp-content/themes/Git-alpha-GiUEQq/assets/img/pic/9.jpg&h=110&w=185&q=90&zc=1&ct=1)