基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库。前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集。
1.安装MySQL
1.1安装MySQL Server
在Ubuntu下面安装MySQL的Server很简单,只需要运行:
sudo apt-get install mysql-server
系统会把MySQL下载并安装好。这里我们可以把MySQL安装在master机器上。
安装后需要配置用户名密码和远程访问。
1.2配置用户名密码
首先我们以root身份登录到mysql服务器:
sudo mysql -u root
然后修改root的密码,并允许root远程访问:
GRANT ALL PRIVILEGES ON *.* TO root@'%' IDENTIFIED BY "";
我们这里还可以为hive建立一个用户,而不是用root用户:
GRANT ALL PRIVILEGES ON *.* TO hive@'%' IDENTIFIED BY "hive";
运行完成后quit命令即可退出mysql的命令行模式。
1.3配置远程访问
默认情况下,MySQL是只允许本机访问的,要允许远程机器访问需要修改配置文件
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
找到bind-address的配置部分,然后改为:
bind-address = 0.0.0.0
保存,重启mysql服务
sudo service mysql restart
重启完成后,我们可以在Windows下,用MySQL的客户端连接master上的MySQL数据库,看是否能够远程访问。
2.下载并配置Hive
2.1下载Hive
首先我们到官方网站,找到Hive的下载地址。http://www.apache.org/dyn/closer.cgi/hive/ 会给出一个建议的网速快的下载地址。
然后在master服务器上,wget下载hive的编译好的文件,我现在最新版是Hive 2.1.1 :
wget http://mirror.bit.edu.cn/apache/hive/hive-2.1.1/apache-hive-2.1.1-bin.tar.gz
下载完成后,解压这个压缩包
tar xf apache-hive-2.1.-bin.tar.gz
按之前Hadoop的惯例,我们还是把Hive安装到/usr/local目录下吧,所以移动Hive文件:
sudo mv apache-hive-2.1.-bin /usr/local/hive
2.2配置环境变量
sudo vi /etc/profile
增加如下配置:
export HIVE_HOME=/usr/local/hive<br/>
export PATH=$PATH:$HIVE_HOME/bin<br/>
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:/usr/local/hive/lib
2.3配置hive-env.sh
<code>所有Hive的配置是在/usr/local/hive/conf目录下,进入这个目录,我们需要先基于模板新建<code>hive-env.sh文件:</code></code>
cp hive-env.sh.template hive-env.sh<br/> vi hive-env.sh
指定Hadoop的路径,增加以下行:
HADOOP_HOME=/usr/local/hadoop
2.4配置hive-site.xml
cp hive-default.xml.template hive-site.xml<br/> vi hive-site.xml
首先增加mysql数据库的连接配置:
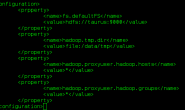
<property><br/> <name>javax.jdo.option.ConnectionURL</name><br/> <value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value><br/> <description>JDBC connect string for a JDBC metastore</description><br/> </property><br/> <property><br/> <name>javax.jdo.option.ConnectionDriverName</name><br/> <value>com.mysql.jdbc.Driver</value><br/> <description>Driver class name for a JDBC metastore</description><br/> </property><br/> <property><br/> <name>javax.jdo.option.ConnectionUserName</name><br/> <value>hive</value><br/> <description>username to use against metastore database</description><br/> </property><br/> <property><br/> <name>javax.jdo.option.ConnectionPassword</name><br/> <value>hive</value><br/> <description>password to use against metastore database</description><br/> </property>
<code>然后需要修改临时文件夹的路径,找到以下2个配置,并改为正确的路径:</code>
<property><br/> <name>hive.exec.local.scratchdir</name><br/> <value>/home/hduser/iotmp</value><br/> <description>Local scratch space for Hive jobs</description><br/> </property><br/> <property><br/> <name>hive.downloaded.resources.dir</name><br/> <value>/home/hduser/iotmp</value><br/> <description>Temporary local directory for added resources in the remote file system.</description><br/> </property>
这里因为我当前用户是hduser,所以我在hduser的目录下创建一个iotmp文件夹,并授权:
mkdir -p /home/hduser/iotmp<br/> chmod -R /home/hduser/iotmp
2.5修改hive-config.sh
<code>进入目录/usr/local/hive/bin</code>
vi hive-config.sh
<code>在该文件的最前面加入以下配置:</code>
export JAVA_HOME=/usr/lib/jvm/java--openjdk-amd64<br/> export HADOOP_HOME=/usr/local/hadoop<br/> export HIVE_HOME=/usr/local/hive
2.6下载MySQL JDBC驱动
去MySQL的官网,https://dev.mysql.com/downloads/connector/j/ 下载JDBC驱动到master服务器上。
wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.40.tar.gz
下载完后解压
tar xf mysql-connector-java-5.1..tar.gz
然后进入解压后的目录,把jar包复制到Hive/lib目录下面
cp mysql-connector-java-5.1.-bin.jar /usr/local/hive/lib/
2.7在HDFS中创建目录和设置权限
启动Hadoop,在Hadoop中创建Hive需要用到的目录并设置好权限:
hadoop fs -mkdir /tmp<br/> hadoop fs -mkdir -p /user/hive/warehouse<br/> hadoop fs -chmod g+w /tmp<br/> hadoop fs -chmod g+w /user/hive/warehouse
2.8初始化meta数据库
<code>进入/usr/local/hive/lib目录,初始化Hive元数据对应的MySQL数据库:</code>
schematool -initSchema -dbType mysql
3.使用Hive
<code>在命令行下,输入hive命令即可进入Hive的命令行模式。我们可以查看当前有哪些数据库,哪些表:</code>
<code>show databases;<br/> show tables;</code>
<code>关于hive命令下有哪些命令,具体介绍,可以参考官方文档:<a href="https://cwiki.apache.org/confluence/display/Hive/Home" rel="external nofollow noreferrer">https://cwiki.apache.org/confluence/display/Hive/Home</a></code>
3.1创建表
<code>和普通的SQL创建表没有太大什么区别,主要是为了方便,我们设定用\t来分割每一行的数据。比如我们要创建一个用户表:</code>
create table Users (ID int,Name String) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
3.2插入数据
<code>是insert语句可以插入单条数据:</code>
insert into Users values(1,'Devin');
<code>如果要导入数据</code>
<code>我们在Ubuntu下创建一个name.txt文件,然后编辑其中的内容,添加如下内容:</code>
2 Edward
3 Mindy
4 Dave
5 Joseph
6 Leo
列直接我是用Tab隔开的。
如果想把这个txt文件导入hive的Users 表,那么只需要在hive中执行:
LOAD DATA LOCAL INPATH '/home/hduser/names.txt' into table Users ;
3.3查询数据
<code>仍然是sql语句:</code>
select * from Users ;
<code>当然我们也可以跟条件的查询语句:</code>
select * from Users where Name like 'D%';
3.4增加一个字段
<code>比如我们要增加生日这个字段,那么语句为:</code>
alter table Users add columns (BirthDate date);
3.5查询表定义
我们看看表的结构是否已经更改,查看Users表的定义:
desc Users;
3.6其他
另外还有重名了表,删除表等,基本也是SQL的语法:
alter table Users rename to Student;
删除一个表中的所有数据:
truncate table Student;
<strong>【另外需要注意,Hive不支持update和delete语句。似乎只有先truncate然后在重新insert。】</strong>
转发申明:
本文转自互联网,由小站整理并发布,在于分享相关技术和知识。版权归原作者所有,如有侵权,请联系本站,将在24小时内删除。谢谢