从零自学Hadoop(22):HBase协处理器
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们讲述了HBase的数据模型相关操作的下部分。
下面我们开始介绍HBase的协处理器部分。
介绍
一:介绍
从0.92版本开始,HBase加入了协处理器(coprocessors),利用协处理器,用户可以编写运行在 HBase Server 端的代码。可以实现“二级索引”,求和、计数、排序、过滤等server端操作。
二:类型
分两种 Observer和Endpoint 。
三:观察者(Observer)
Observer 协处理器类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子,在固定的事件发生时被调用。比如:put 操作之前有钩子函数 prePut,该函数在 put 操作执行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数
四:终端(Endpoint)
Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器执行一段 Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理,最常见的用法就是进行聚集操作。如果没有协处理器,当用户需要找出一张表中的最大数据,即 max 聚合操作,就必须进行全表扫描,在客户端代码内遍历扫描结果,并执行求最大值的操作。这样的方法无法利用底层集群的并发能力,而将所有计算都集中到 Client 端统一执行,势必效率低下。利用 Coprocessor,用户可以将求最大值的代码部署到 HBase Server 端,HBase 将利用底层 cluster 的多个节点并发执行求最大值的操作。即在每个 Region 范围内执行求最大值的代码,将每个 Region 的最大值在 Region Server 端计算出,仅仅将该 max 值返回给客户端。在客户端进一步将多个 Region 的最大值进一步处理而找到其中的最大值。这样整体的执行效率就会提高很多。
Observer操作
一:说明
我们编写一个类,使每次put进来的数据都打印日志,用来测试observer coprocessor的机制。
二:编写协处理器工程
package com.du.hbase.coprocessor; import java.io.IOException;<br/> import org.apache.hadoop.hbase.Cell;<br/> import org.apache.hadoop.hbase.CellScanner;<br/> import org.apache.hadoop.hbase.CellUtil;<br/> import org.apache.hadoop.hbase.client.Durability;<br/> import org.apache.hadoop.hbase.client.Put;<br/> import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;<br/> import org.apache.hadoop.hbase.coprocessor.ObserverContext;<br/> import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;<br/> import org.apache.hadoop.hbase.regionserver.wal.WALEdit;<br/> import org.apache.log4j.Logger; /**<br/> * @FileName : (CP_writelog.java)<br/> *<br/> * @description :协处理器写日志<br/> * @author : Frank.Du<br/> * @version : Version No.1<br/> * @create : 2016年12月8日 下午6:52:31<br/> * @modify : 2016年12月8日 下午6:52:31<br/> * @copyright :<br/> */<br/> public class CP_writelog extends BaseRegionObserver {<br/> private static final Logger logger = Logger.getLogger(CP_writelog.class); @Override<br/> public void prePut(ObserverContext<RegionCoprocessorEnvironment> e,<br/> Put put, WALEdit edit, Durability durability) throws IOException { writeLog(put); super.prePut(e, put, edit, durability);<br/> } /**<br/> * 写log<br/> *<br/> * @param put<br/> * @throws IOException<br/> */<br/> private void writeLog(Put put) {<br/> try {<br/> logger.info("writehdfs : is begining");<br/> CellScanner cellScanner = put.cellScanner(); StringBuilder sb = new StringBuilder();<br/> while (cellScanner.advance()) {<br/> Cell current = cellScanner.current();<br/> String fieldName = new String(CellUtil.cloneQualifier(current),<br/> "utf-8");<br/> String fieldValue = new String(CellUtil.cloneValue(current),<br/> "utf-8");<br/> String fieldRow = new String(CellUtil.cloneRow(current),<br/> "utf-8"); String fieldFamilyCell = new String(<br/> CellUtil.cloneFamily(current), "utf-8");<br/> String info = "fieldName:" + fieldName + " fieldValue:"<br/> + fieldValue + " fieldRow:" + fieldRow<br/> + " fieldFamilyCell:" + fieldFamilyCell; sb.append(info);<br/> } logger.info("writehdfs : info:" + sb.toString()); } catch (IOException e) {<br/> logger.error(e.getMessage());<br/> } } }三:使用maven打包程序
由于打包的jar包名字太长,将jar包改成hbase-cp.jar
四:将文件上传到linux本地系统
put 'table1','row1','cf3:a','aa2'通过xshell工具,将协处理程序上传到linux服务器下。
五:将本地文件上传到hdfs文件系统中
sudo -uhdfs hadoop fs -copyFromLocal hbase-cp.jar /user/hbase-cp.jar
六:进入hbase shell
hbase shell
七:查看table1的表信息
desc 'table1'
由此可见,该表没有设置协处理器。
八:添加协处理器
alter 'table1','coprocessor'=>'hdfs://master4:8020/user/hbase-cp.jar|com.du.hbase.coprocessor.CP_writelog|1001'中间一段为协处理的jar包和类名
最后一段数字为权值,权值越小,协处理器的执行越靠前九:查看table1的表信息
desc 'table1'
可以看到该表已经设置了协处理器。
十:查看该表所在RegionServer
打开网页http://master4:16010/master-status
点击进去
可以看到regionserver是master4。
十一:查看日志
进入对应regionserver
cd /var/log/hbase/查看日志
tail -2000f hbase-hbase-regionserver-master4.log
十二:插入数据
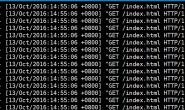
put 'table1','row11','cf1:a','v11'在插入数据的过程中。我们同时看下日志
可以看到我们插入的数据,在日志里打印出来了。
十三:删除协处理器
alter 'table1',METHOD=>'table_att_unset' ,NAME=>'coprocessor$1'
——————————————————————–
到此,本章节的内容讲述完毕。
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
:HBase协处理器")
示例下载
github:https://github.com/sinodzh/HadoopExample/tree/master/2016/hbase
系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
转发申明:
本文转自互联网,由小站整理并发布,在于分享相关技术和知识。版权归原作者所有,如有侵权,请联系本站,将在24小时内删除。谢谢