前言:row_number,sql,hive,窗口函数,数仓,大数据
以sql为基础,利用题目进行hive的语句练习,逐步体会sql与hive的不同之处。
本次题目用到row_number()、collect_set()、concat_ws()。
其中collect_set()、concat_ws讲解可参考
https://www.jianshu.com/p/6ec508d1591a
文末讲解row_number。
题目:
存在一份数据
userid,changjing,inttime
1,1001,1400
2,1002,1401
1,1002,1402
1,1001,1402
2,1003,1403
2,1004,1404
3,1003,1400
4,1004,1402
4,1003,1403
4,1001,1403
4,1002,1404
5,1001,1402
5,1001,1403
:面试题——场景输出(row_number)")
image.png
要求输出,用户号对应前两个不同场景
1-1001-1002
2-1002-1003
3-1003
4-1004-1003
5-1001
解题步骤:
一、创建表mianshi1
hive> create table mianshi1(userid string,changjing string,inttime int)
row format delimited fields terminated by ",";
二、导入数据
hive> load data local inpath"/home/jiafeng/xxx.csv" into table mianshi1;
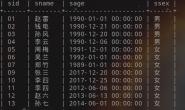
三、验证数据是否准确
hive> select * from mianshi1;
:面试题——场景输出(row_number)")
image.png
四、按inttime时间进行排序
hive> create table tmp_mianshi1 as
> select *,row_number() over(partition by userid order by inttime) as num
from mianshi1 order by userid,inttime;
:面试题——场景输出(row_number)")
image.png
五、筛选出前两个不同的场景
hive> create table tmp1_mianshi1 as
> select userid,collect_set(changjing) as changjing2 from
tmp_mianshi1 where num<=2 group by userid;
:面试题——场景输出(row_number)")
image.png
六、获得答案结果
方法一:
hive> select concat(userid,"-",concat_ws("-",changjing2)) as result
from tmp1_mianshi1;
:面试题——场景输出(row_number)")
image.png
方法二:
hive> select
(case when changjing2[1] is NULL then concat(userid,"-",changjing2[0])
else concat(userid,"-",changjing2[0],"-",changjing2[1]) end) as result
from tmp1_mianshi1;
注:方法二适用场景更多,concat_ws函数只适用string类型,做题过程中表类型设置为int,最终获得了array<int>,无法利用类型转换为array<string>(会报错)。
讲解
row_number()
- 遇相同数据依旧会排序,
例如:小明80分,小红80分,小张75分,排序为:小明 1 小红 2 小张3 - 通常结合partition by xxx order by xxx (asc/desc)使用
亦或者distribute by xxx sort by xxx(asc/desc)
partition by 即分组,order by 为排序 - 实际案例:
select * from tmp_test;
c1 c2
----- ------
1 str1
2 str2
3 str3
3 str31
3 str33
4 str41
4 str42
select t.*,row_number() over(distribute by c1 sort by c2 desc) rn
from tmp_test t;
c1 c2 rn
_________
1 str1 1
2 str2 1
3 str33 1
3 str31 2
3 str3 3
4 str42 1
4 str41 2