- 本文种记录的大多是开源版本hive调优方式
- 我也会补充TDH集群Inceptor的优化方式
面试必备技能-HiveSQL优化
Hive SQL基本上适用大数据领域离线数据处理的大部分场景.Hive SQL的优化也是我们必须掌握的技能,而且,面试一定会问.那么,我希望面试者能答出其中的80%优化点,在这个问题上才算过关.
Hive优化目标
- 在有限的资源下,执行效率更高
常见问题
- 数据倾斜
- map数设置
- reduce数设置
- 其他
Hive执行
- HQL –> Job –> Map/Reduce
- 执行计划
- explain [extended] hql
- 样例
select col,count(1) from test2 group by col; explain select col,count(1) from test2 group by col;
各个阶段
Hive表优化
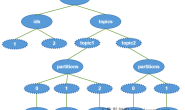
- 分区
set hive.exec.dynamic.partition=true;set hive.exec.dynamic.partition.mode=nonstrict;- 静态分区(单值、范围)
- 动态分区(单值)
- 分桶(小小经验)
set hive.enforce.bucketing=true;set hive.enforce.sorting=true;
- 数据
- 相同数据尽量聚集在一起
Hive Job优化
- 并行化执行
-- 每个查询被hive转化成多个阶段,有些阶段关联性不大,则可以并行化执行,减少执行时间 set hive.exec.parallel= true; set hive.exec.parallel.thread.numbe=8; - 本地化执行
-- job的输入数据大小必须小于参数:hive.exec.mode.local.auto.inputbytes.max(默认128MB) -- job的map数必须小于参数:hive.exec.mode.local.auto.tasks.max(默认4) -- job的reduce数必须为0或者1 set hive.exec.mode.local.auto=true; - 当一个job满足如下条件才能真正使用本地模式:
- job合并输入小文件
-- 合并文件数由mapred.max.split.size限制的大小决定 set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat - job合并输出小文件
-- 当输出文件平均小于该值,启动新job合并文件 set hive.merge.smallfiles.avgsize=256000000; -- 合并之后的文件大小 set hive.merge.size.per.task=64000000;
- job合并输入小文件
- JVM重利用
set mapred.job.reuse.jvm.num.tasks=20;JVM重利用可以使得Job长时间保留slot,直到作业结束,这在对于有较多任务和较多小文件的任务是非常有意义的,减少执行时间.当然这个值不能设置过大,因为有些作业会有reduce任务,如果reduce任务没有完成,则map任务占用的slot不能释放,其他的作业可能就需要等待.
- 压缩数据
set hive.exec.compress.output=true;
set mapred.output.compreession.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compression.type=BLOCK;
set hive.exec.compress.intermediate=true;
set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
set hive.intermediate.compression.type=BLOCK;
中间压缩就是处理hive查询的多个job之间的数据,对于中间压缩,最好选择一个节省cpu耗时的压缩方式
hive查询最终的输出也可以压缩
Hive Map优化
set mapred.map.tasks =10; 无效
- 默认map个数
default_num=total_size/block_size; - 期望大小
goal_num=mapred.map.tasks; - 设置处理的文件大小
split_size=max(mapred.min.split.size,block_size);
split_num=total_size/split_size; - 计算的map个数
compute_map_num=min(split_num,max(default_num,goal_num))
经过以上的分析,在设置map个数的时候,可以简答的总结为以下几点:
- 增大
mapred.min.split.size的值 - 如果想增加map个数,则设置
mapred.map.tasks为一个较大的值 - 如果想减小map个数,则设置
mapred.min.split.size为一个较大的值- 情况1:输入文件size巨大,但不是小文件
- 情况2:输入文件数量巨大,且都是小文件,就是单个文件的size小于blockSize.这种情况通过增大
mapred.min.split.size不可行,需要使用combineFileInputFormat将多个input path合并成一个InputSplit送给mapper处理,从而减少mapper的数量.
- map端聚合
set hive.map.aggr=true; - 推测执行
mapred.map.tasks.apeculative.execution
Hive Shuffle优化
- Map端
io.sort.mb
io.sort.spill.percent
min.num.spill.for.combine
io.sort.factor
io.sort.record.percent
- Reduce端
mapred.reduce.parallel.copies
mapred.reduce.copy.backoff
io.sort.factor
mapred.job.shuffle.input.buffer.percent
mapred.job.shuffle.input.buffer.percent
mapred.job.shuffle.input.buffer.percent
Hive Reduce优化
- 需要reduce操作的查询
group by,join,distribute by,cluster by... - order by比较特殊,只需要一个reduce
sum,count,distinct... - 聚合函数
- 高级查询
- 推测执行
mapred.reduce.tasks.speculative.execution
hive.mapred.reduce.tasks.speculative.execution
- Reduce优化
numRTasks = min[maxReducers,input.size/perReducer]
maxReducers=hive.exec.reducers.max
perReducer = hive.exec.reducers.bytes.per.reducer
hive.exec.reducers.max -- 默认: 999
hive.exec.reducers.bytes.per.reducer -- 默认: 1G
set mapred.reduce.tasks=10; -- 直接设置
计算公式
Hive查询操作优化
- common join
-- common join也叫做shuffle join,reduce join操作.
-- 这种情况下生再两个table的大小相当,但是又不是很大的情况下使用的.
-- 具体流程就是在map端进行数据的切分,一个block对应一个map操作,然后进行shuffle操作,把对应的block shuffle到reduce端去,再逐个进行联合,这里优势会涉及到数据的倾斜,大幅度的影响性能有可能会运行speculation
-- 如果是Join过程出现倾斜,应该设置为true
set hive.optimize.skewjoin=true;
-- 这个是join的键对应的记录条数超过这个值则会进行优化
set hive.skewjoin.key=100000;
- map join:
-- 把小的表加入内存,可以配置这个参数,使hive自动根据sql,选择使用common join或者map join.
-- map join并不会涉及reduce操作.map端join的优势就是在于没有shuffle
set hive.auto.convert.join = true;
-- 小表的最大文件大小,默认为25000000,即25M
set hive.mapjoin.smalltable.filesize = 25000000;
关联参考
-- 是否将多个mapjoin合并为一个
set hive.auto.convert.join.noconditionaltask = true;
-- 多个mapjoin转换为1个时,所有小表的文件大小总和的最大值.
set hive.auto.convert.join.noconditionaltask.size = 10000000;
-- 如果是Join过程出现倾斜,应该设置为true
set hive.optimize.skewjoin=true;
-- 这个是join的键对应的记录条数超过这个值则会进行优化
set hive.skewjoin.key=100000;
- SMBJoin(sort merge bucket)
- 两个表以相同方式划分桶
- 两个表的桶个数是倍数关系
CRETE TABLE order(cid int,price float) CLUSTERED BY(cid) INTO 3 BUCKETS;
CRETE TABLE customer(id int,first string)
CLUSTERED BY(id) INTO 3 BUCKETS;
SELECT t.price
FROM order t JOIN customer t2 ON t.cid=t2.id
-- join优化前查询语句
SELECT t.cid,t2.id
FROM order t join customer t2 ON t.cid=t2.id
WHERE t.dt='2013-12-12';
-- join优化后查询语句
SELECT t.cid,t2.id
FROM (
SELECT cid FROM order
WHERE dt='2013-12-12'
) t JOIN customer t2 ON t.cid=t2.id;
- group by 优化
-- 如果是group by 过程出现倾斜 应该设置为true
set hive.groupby.skewindata=true;
-- 这个是group的键对应的记录条数超过这个值则会进行优化
set hive.groupby.mapaggr.checkinterval=100000;
- count distinct 优化
-- 优化前查询语句
SELECT COUNT(distinct id) FROM tablename
-- 优化后查询语句
SELECT count(1) FROM (SELECT DISTINCT id FROM tablename) tmp;
SELECT count(1) FROM (SELECT id FROM tablename group by id) tmp;
-- 优化前sum语句
SELECT
a
,sum(b)
,count(DISTINCT c)
,count(DISTINCT d)
FROM test
GROUP BY a
-- 优化后sum语句
SELECT
a
,sum(b) AS b
,count(c) AS c
,count(d) AS d
FROM
(
SELECT a, 0 AS b, c, NULL AS d FROM test GROUP BY a, c
UNION ALL
SELECT a, 0 AS b, NULL AS c, d FROM test GROUP BY a, d
UNION ALL
SELECT a, b, NULL AS c, NULL AS d FROM test
) tmp1
GROUP BY a;
参考
《面试必备技能-HiveSQL优化》文中错误之处,我已在本文改正
《hive中的mapjoin》
《hive入门学习:join的三种优化方式》