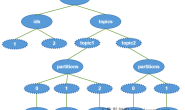
- 为什么做分区
分区表将数据组织成分区,主要可以提高数据的查询速度。
如果把一年或者一个月的日志文件存放在一个表下,那么数据量会非常的大,当查询这个表中某一天的日志文件的时候,查询速度还非常的慢,这时候可以采用分区表的方式,把这个表根据时间点再划分为小表。这样划分后,查询某一个时间点的日志文件就会快很多,因为这是不需要进行全表扫描。
Hive中的分区是根据“分区列”的值对表的数据进行粗略的划分,Hive中一个表对应一个目录,再根据分区列在这个表目录下创建子目录,每个子目录名就是分区列的名字。分区列定义与表中字段相似,但是与表中的字段无关,是独立的列。这样就加快了数据查询的速度,因为不会对这个表中进行全盘扫描了。
- 如何做分区
(1)建表语句
create table if not exists latte_d_test
(
uid string comment “用户ID”,
vld_flg string comment “该条记录是否有效,1-有效,0-无效”
)
COMMENT “test表”
PARTITIONED BY (day STRING);
(2)设置分区表参数
set hive.exec.dynamic.partition = true;
设置为true表示开启动态分区功能(默认为false)。
set hive.exec.dynamic.partition.mode = nonstrict;
设置为nonstrict,表示允许所有分区都是动态的(默认为strict)。
(3)插入数据
insert overwrite table latte_d_test partition(day)
select uid,
‘1’,
‘2016-10-10’
from test