背景
最近由Java工程师转岗为ETL数据工程师,虽然以前也有为数据集成的项目储备过kettle相关的知识,但是一直没有在生产环境中实际使用过kettle。然后最近刚好有一个比较小的活,需要每天定时同步几个csv文件到数据库表,然后用kettle大概花了一天时间做完了这个任务。
需求:将每天上传到指定目录下.tar.gz压缩包下的4个csv文件,每天定时同步到数据库表中。
解题思路
- 首先对压缩文件解压,解压.tar.gz文件,得到4个csv文件。
- 然后对4个csv文件使用kettle,输出到数据库表。
- 使用linux crontab 定时调用脚本完成每天的同步任务。
kettle Job流程
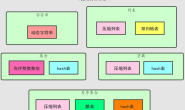
下面是同步csv文件Job的整体流程,整体流程是如下:
设置当前日期变量->清除表数据->同步csv到数据库*4->成功/失败邮件

1. 设置当前日期变量
因为csv文件都是有日期后缀的,每天一个,所以获取csv文件名的时候需要拼一个当前日期字符串。因为后面4个同步csv的转换都需要这个日期字符串,所以单独用一个转换来处理这个日期字符串,然后设置到环境变量,后面的几个转换,再获取这个日期字符串,这个转换主要有3步:
获取系统时间->时间格式化->设置时间变量到环境变量,其中时间格式化是采用JavaScript插件来处理:

在设置时间变量步骤中,需要注意,设置的环境变量是通过第二列的${FILEDATE}来获取,而不是第一列的字段名

2. 清除表数据
通过sql插件来清除4张表数据。
3. 同步CSV文件到数据库表
这部分是主要的流程,CSV文件是以当前日期结尾的,不是固定的,所以一开始需要处理csv文件名,动态拼接日期字符串。流程如下:
获取当前日期变量->处理文件名字符串->CSV文件输入->表输出

处理文件名字符串字符串使用的是公式插件,然后拼接日期参数:

csv文件输入的时候,需要选择从上一步骤获取文件名,然后因为没有从本地选择本地文件,所以无法获取字段,可以创建一个从本地文件读取的csv输入,获取字段Copy下来,然后黏贴到下面字段列表里。

shell脚本来处理压缩文件和执行Job任务
通过linux crontab 定时执行shell脚本来解压文件,以及执行kettle的Job任务。解压tar.gz文件到指定目录,然后再调用kettle kitchen命令来执行Job。
1. 处理压缩文件脚本如下:

2. 执行ETL Job任务脚本如下:

欢迎大家赞赏、转载、点赞、评论。