技术选型
filebeat简介

- processors配置: 可以对event做很多加工, 比如add_fields,add_labels, add_tags, rename, drop_event等等
- Inputs配置: 定义各种input配置。
- Moduels: 对各种开源组件的日志收集支持,这些modules针对各个组件的日志做了parse与结构化处理,同时集成了ES, Kibana, 为这些开源组件提供一整套日志收集展示方案。
- HTTP endpoint: 配置http rest api获取metrics。
filebeat收集meta持久化机制
{"op":"set","id":1}{"k":"filebeat::logs::native::3162611-64768","v":{"id":"native::3162611-64768","prev_id":"","source":"/root/ysptest1.log","offset":0,"ttl":-1,"type":"log","timestamp":[2061828726851,1628151202],"FileStateOS":{"inode":3162611,"device":64768},"identifier_name":"native"}}{"op":"set","id":2}{"k":"filebeat::logs::native::3162611-64768","v":{"id":"native::3162611-64768","prev_id":"","timestamp":[2061975276931,1628151203],"ttl":-1,"FileStateOS":{"inode":3162611,"device":64768},"identifier_name":"native","source":"/root/ysptest1.log","offset":165,"type":"log"}}其中记录了input type, source端文件路径以及当前收集到的offset,时间戳, 还有用于唯一标识文件的inode, device信息。ack确认反馈会从output端一直反馈到input端,input端收到ack确认后会负责将meta信息持久化到这个文件中。
filebeat反压机制
日志收集方案
设计目标:
- 提供统一运维监控管理,降低运维成本。
- 收集的日志可以同时满足实时,离线需求。
- 日志收集pipeline支持反压,支持at least once语义,支持日志重放。
- 跨IDC容灾,支持动态修改agent配置,将日志收集定向到其他IDC。
设计方案:
- 提供一键agent部署脚本,提供agentManager管理metrcis上报与agent配置修改动态感知
- 将kafka作为统一日志收集目的地。
- logstash 作为日志汇聚层, 避免agent过多对kafka带来压力。
- 监控告警: 获取filebeat,logstash metrics并解析成prom格式上报给prometheus, 通过grafana展示,提供实例级别的监控,对收集延迟,失败及时告警, 对收集的日志count进行统计,方便对数。
- 产品化集成到ultron平台,基于项目粒度进行统一管理,运维,监控。
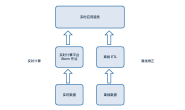
以下是日志收集的总体架构示意图:

对于日志收集处理可以分为如下四个层次:
#Q1 日志收集agent层:
#Q2 日志汇聚层:
这是个可选层,分以下两种情况:
- 对于agent不是很多的case, 直接采用filebeat + kafka的方案是很高效的
- 对于agent很多的case,我们提供logstash汇聚层来对收集数据汇总然后发送给kafka, 避免对kafka造成连接过多的问题
#Q3 DataBus层:
我们将日志采集统一到kafka, 这样离线实时需求都可以得到满足, 我们在每个IDC都有kafka集群,这样当某个IDC不可用时,动态修改filebeat配置即可完成重新收集,相当于具备了跨IDC容灾的能力。
#Q4 异构传输层:
这一层主要是对收集日志的处理使用, 我们当前通过自研的hamal2落地hdfs/hive为离线etl提供支持, 通过flink/spark/storm/druid/clickhouse等实时消费处理。hamal2是我们基于flink实现的一个异构数据同步传输框架,用于Kafka数据实时入仓入湖。
下面主要介绍两种方案:
- filebeat —> kafka 直连, 这是目前主要在用的方案。
- filebeat —> logstash —> kafka 这个方案加入了logstash汇聚层。
filebeat —> kafka
对于agent不是很多的场景, 直接使用filebeat kafka output写入kafka是高效简洁的方式, 根据我们上面阐述的filebeat收集meta持久化机制和反压机制,在kafka有问题写入不成功的情况下,会触发filebeat反压, 日志收集文件的offset也将停止持久化,这样是符合我们预期的。目前360商业化没有有很多agent的场景, 所以主要使用这种模式。
下面是filebeat–>kafka的简单架构示意图:

filebeat.yml 配置示例:
filebeat.inputs:- type: logenabled: truepaths:- /root/test*.logfields:topic_name: test- type: logenabled: truepaths:- /root/test2*.logfields:topic_name: test2output.kafka:version: 2.0.0hosts: ["xxx:9092", "xxx:9092", "xxx:9092"]# message topic selection + partitioningtopic: '%{[fields.topic_name]}'partition.round_robin:reachable_only: falserequired_acks: 1compression: lz4max_message_bytes: 10000000sasl.mechanism: SCRAM-SHA-256username: xxxpassword: xxxworker: 1 # producer实例数refresh_frequency: 5mcodec.format:string: '%{[message]}' # 定义输出的日志,默认是带有很多meta信息的json stringfilebeat.config.modules:path: ${path.config}/modules.d/*.ymlreload.enabled: false# 定义http endpoint, 用于获取metricshttp.enabled: truehttp.host: your hosthttp.port: 5066
还有比较重要的配置是codec.format,可以重新定义输出日志的格式。
filebeat–>logstash–>kafka
- persistent queues(PQ): 默认是不开启的,日志会先写内存queue再output出去,但这种方式在异常情况下会丢数据, 为了保证日志完整性,我们必须开启PQ,开启后所有日志将先持久化到disk然后再output出去, 这样可以做到at least once语义,可以通过配置queue.type来开启PQ:
queue.type: persistedqueue.max_bytes: 8gbqueue.max_events: 3000000path.queue: /path/to/queuefile
- 反压机制: 在PQ写满的情况下会反压到上游filebeat, filebeat再反压到input停止日志收集。这种反压传导机制和flink的有点像。
通过logstash的PQ机制以及反压机制就可以保证在极端情况下整个pipeline的at least once语义。
下面是filebeat–>logstash–>kafka的简单架构示意图:

filebeat.yml 示例:
filebeat.inputs:- type: logenabled: truepaths:- /root/test*.logfields:topic_name: testkafka_cluster: cluster1- type: logenabled: truepaths:- /root/test2*.logfields:topic_name: test2kafka_cluster: cluster2output.logstash:hosts: ["logstash.k8s.domain:5044"]# 定义http endpoint, 用于获取metricshttp.enabled: truehttp.host: your hosthttp.port: 5066
output.logstash中定义的logstash.k8s.domain:5044 其实是一个lvs域名端口,其后对应了多个logstash实例。这里我们没有使用filebeat的loadbalance设置,因为不是很灵活。
logstash.yml示例
queue.type: persistedqueue.max_bytes: 8gbqueue.max_events: 3000000path.queue: /path/to/queuefile
logstash-pipeline.conf 示例
input {beats {port => "5044"}}filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}"}}}output {stdout { codec => rubydebug {metadata => true}}if [fields][kafka_cluster] == "xxx" { # 日志分拣kafka {codec => plain {format => '{ message:"%{message}"}'}bootstrap_servers => "xxx:9092,xxx:9092,xxx:9092"topic_id => "%{[fields][topic_name]}"compression_type => "lz4"}}if [fields][kafka_cluster] == "xxx" { # 日志分拣kafka {codec => plain {format => '{ message:"%{message}"}'}bootstrap_servers => "xxx:9092,xxx:9092,xxx:9092"topic_id => "%{[fields][topic_name]}"jaas_path => "/root/logstash/kafka-jaas.conf" # 支持SASL SCRAMsasl_mechanism => "SCRAM-SHA-256"security_protocol => "SASL_PLAINTEXT"compression_type => "lz4"}}}
监控
以下是filebeat监控截图, 主要就是将http endpoint中的metrics都展示出来:

总结
参考资料
https://www.elastic.co/guide/en/beats/filebeat/current/index.html
https://www.elastic.co/guide/en/logstash/current/index.html
https://cloud.tencent.com/developer/article/1634020